|
Yang Zhou (周旸) Yang Zhou here. I am a PhD student at Carnegie Mellon University, fortunately working with Prof. Beidi Chen. Previously, I was fortunate to work with Prof. Diana Marculescu on EdgeAI and with Prof. Kurt Keutzer on model quantization. I obtained my bachelor degree at The University of Texas at Austin, studying Electrical and Computer Engineering. My current research focus lies in understanding and improving Large Language Models' reasoning and planning ability with special attention for inference scaling efficiency. I am eager to explore and welcome meaningful collaborations of any kind. If you are aligned with my research direction and would like to discuss, please don't hesitate to reach out. Email / CV / Google Scholar / X/Twitter / Github |

|
🗞️ Latest News
-
May 2024
"GSM-Infinite" accepted at ICML. -
March 2024
Gave a talk about GSM-Infinite at UMD on GSM-Infinite. [Link] -
February 2024
Invited talk about GSM-Infinite at NVIDIA hosted by Dr. Boris Ginsberg. -
February 2024
GSM-Infinite talk featured on the ASAP Seminar. [Watch] -
September 2023
"Sirius" paper accepted at NeurIPS. -
February 2024
"LLM Unveiled" survey paper posted on ArXiv. -
August 2023
Began graduate studies at Carnegie Mellon University. -
May 2023
Graduated from UT Austin for my bachelor degree.
ResearchMost of them related to model compression with the focus of efficiency. Some are Highlighted. (Updated in May 2025) |
|
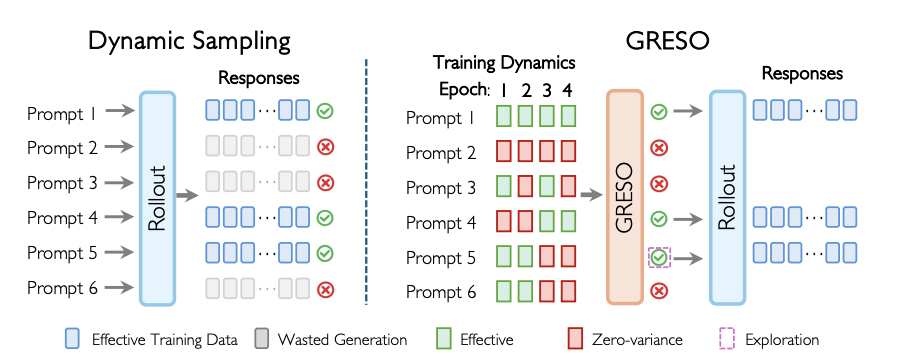
Act Only When It Pays: Efficient Reinforcement Learning for LLM Reasoning via Selective Rollouts
Haizhong Zheng, Yang Zhou Zhuoming Chen, Brian R. Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, Beidi Chen NeurIPS, 2025 project page / arXiv / code / In this paper, we first show that a substantial portion of this overhead can be avoided by skipping uninformative prompts before rollout. Our analysis of reward dynamics reveals a strong temporal consistency in prompt value: prompts that are uninformative in one epoch of training are likely to remain uninformative in near future epochs. Based on these insights, we propose GRESO (GRPO with Efficient Selective Rollout), an online, lightweight pre-rollout filtering algorithm that predicts and skips uninformative prompts using reward training dynamics. |
|
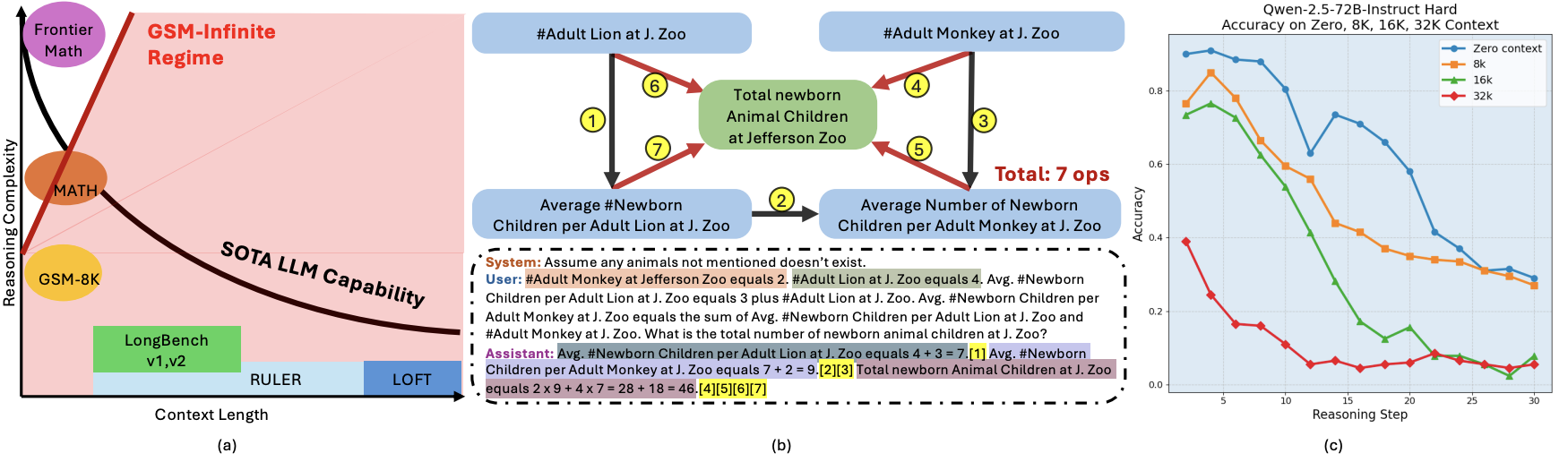
GSM-Infinite: How Do Your LLMs Behave over Infinitely Increasing Context Length and Reasoning Complexity?
Yang Zhou*, Hongyi Liu*, Zhuoming Chen, Yuandong Tian, Beidi Chen *means Equal Contribution ICML, 2025 project page / arXiv / code / ASAP Seminar Talk Inspired by the abstraction of GSM-8K problems as computational graphs—and the ability to introduce noise by adding unnecessary nodes and edge—we develop a grade-school math problem generator capable of producing arithmetic problems with infinite difficulty and context length under fine-grained control. Using our newly synthesized GSM-Infinite benchmark, we comprehensively evaluate existing long-context LLMs. |
|
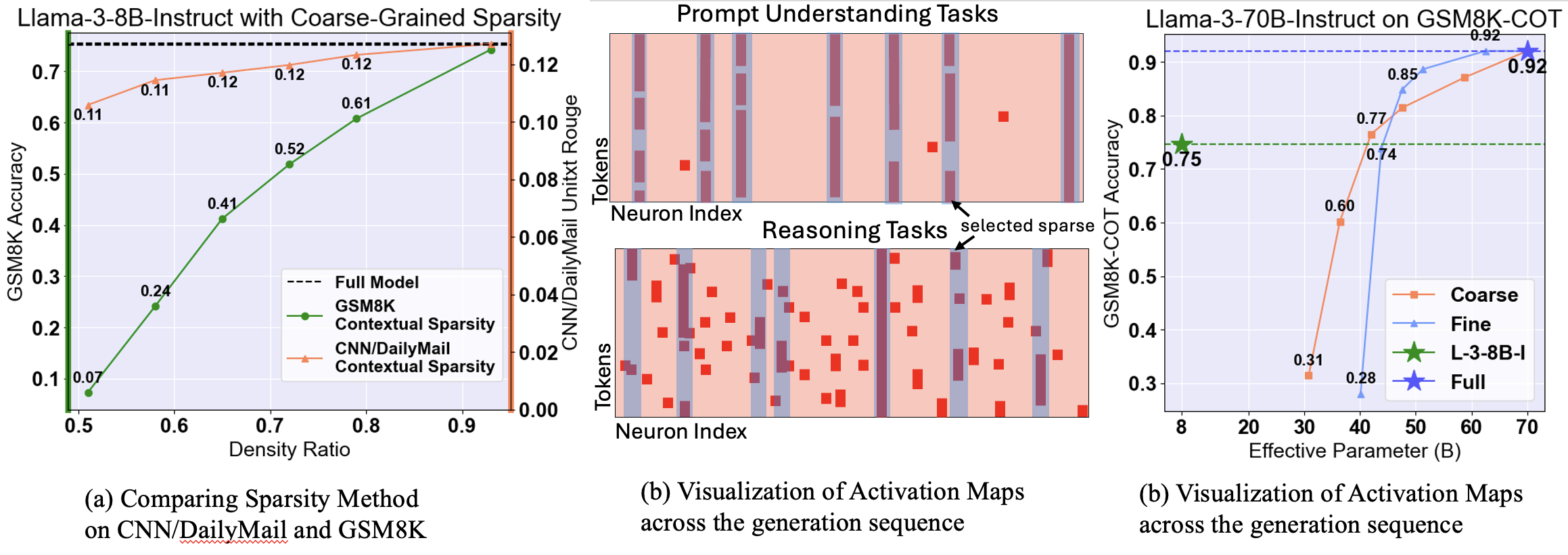
Sirius: Contextual Sparsity with Correction for Efficient LLM
Yang Zhou, Zhuoming Chen, Zhaozhuo Xu, Victoria Lin, Beidi Chen NeurIPS, 2024 project page / arXiv / code We reveal that contextual sparsity struggles at complex reasoning tasks. We propose a efficient correction method to recover the accuracy degradation of contextual sparsity models while maintaining their efficiency. |
|
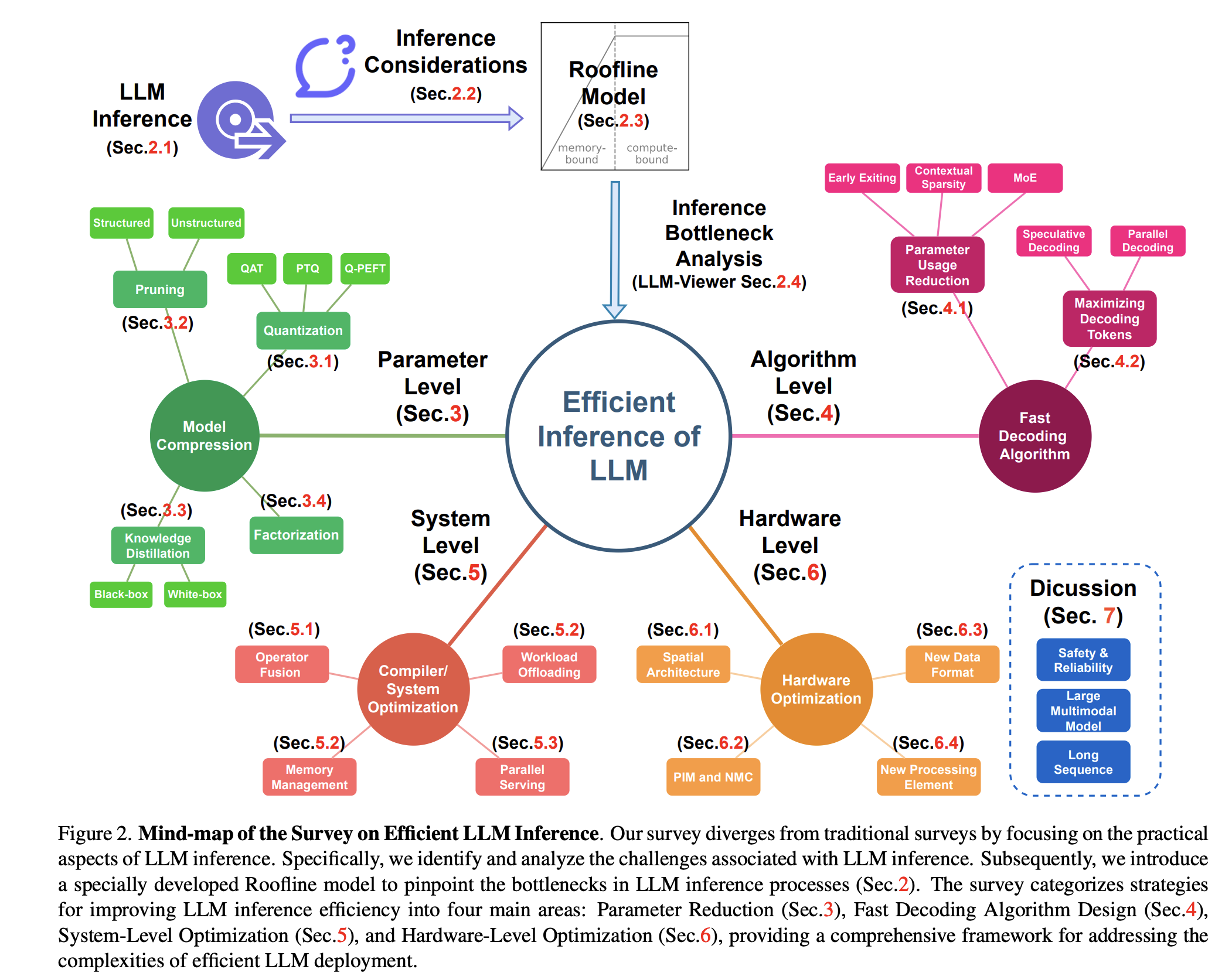
LLM Inference Unveiled: Survey and Roofline Model Insights
Zhihang Yuan*, Yuzhang Shang*, Yang Zhou*, Zhen Dong, Zhe Zhou, Chenhao Xue, Bingzhe Wu, Zhikai Li, Qingyi Gu, Yong Jae Lee, Yan Yan, Beidi Chen, Guangyu Sun, Kurt Keutzer Manuscript, 2024 LLM-Viewer / arXiv We breakdown the LLM inference memory bottlenecks and present algorithm/hardware/system considerations in improving the serving/inference of LLMs. Besides presenting a comprehensive summary of previous works in LLM inference optimation from algorithm, system, and hardware perspectives, we also introduce a roofline modeling tool called LLM-Viewer. LLM-Viewer helps LLM practitioners to visualize their workflow taylored to their specific LLM model and hardware setup. |
|
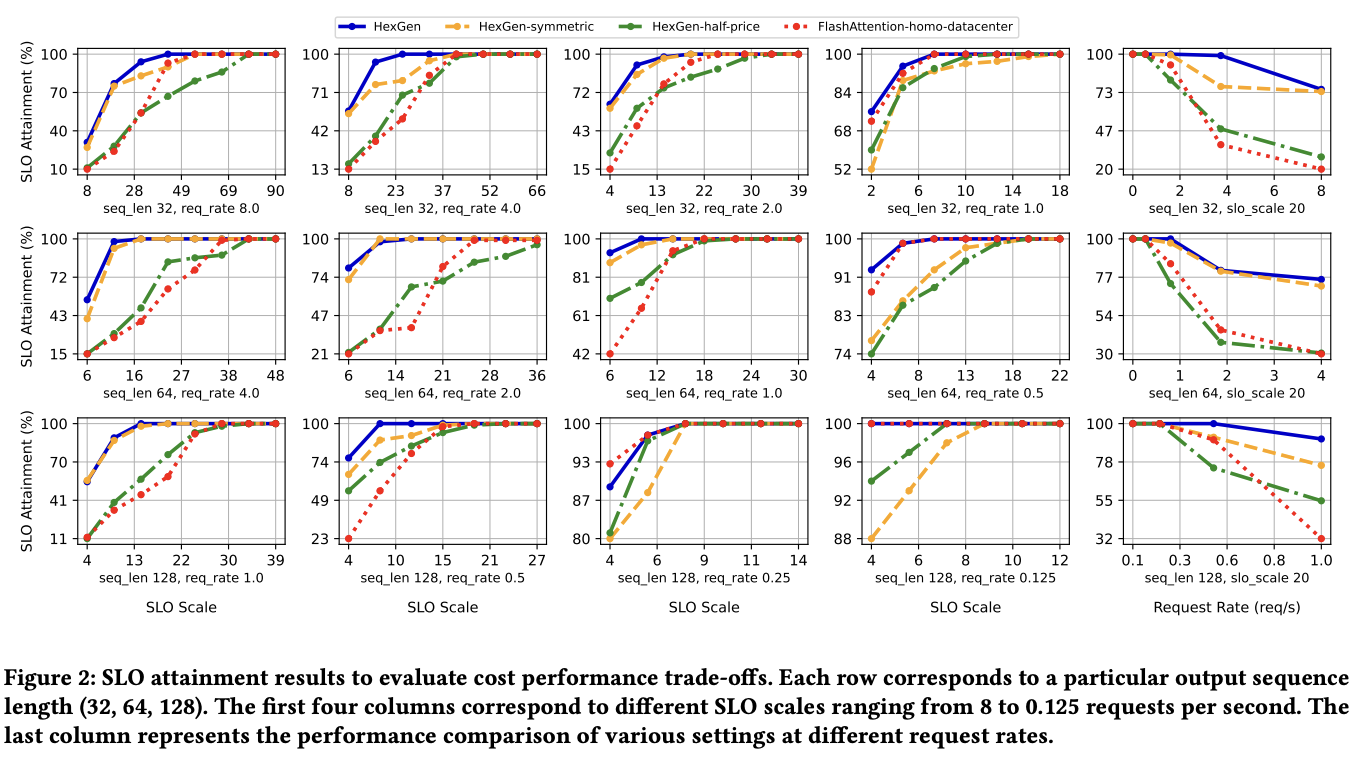
HexGen: Generative Inference of Large-Scale Foundation Model over Heterogeneous Decentralized Environment
Youhe Jiang, Ran Yan, Xiaozhe Yao, Yang Zhou, Beidi Chen, Binhang Yuan ICML 2024, 2023 arXiv link This paper focuses on deploying such services in a heterogeneous and decentralized setting to mitigate the substantial inference costs typically associated with centralized data centers. Towards this end, we propose HexGen, a flexible distributed inference engine that uniquely supports the asymmetric partition of generative inference computations over both tensor model parallelism and pipeline parallelism and allows for effective deployment across diverse GPUs interconnected by a fully heterogeneous network. |
|
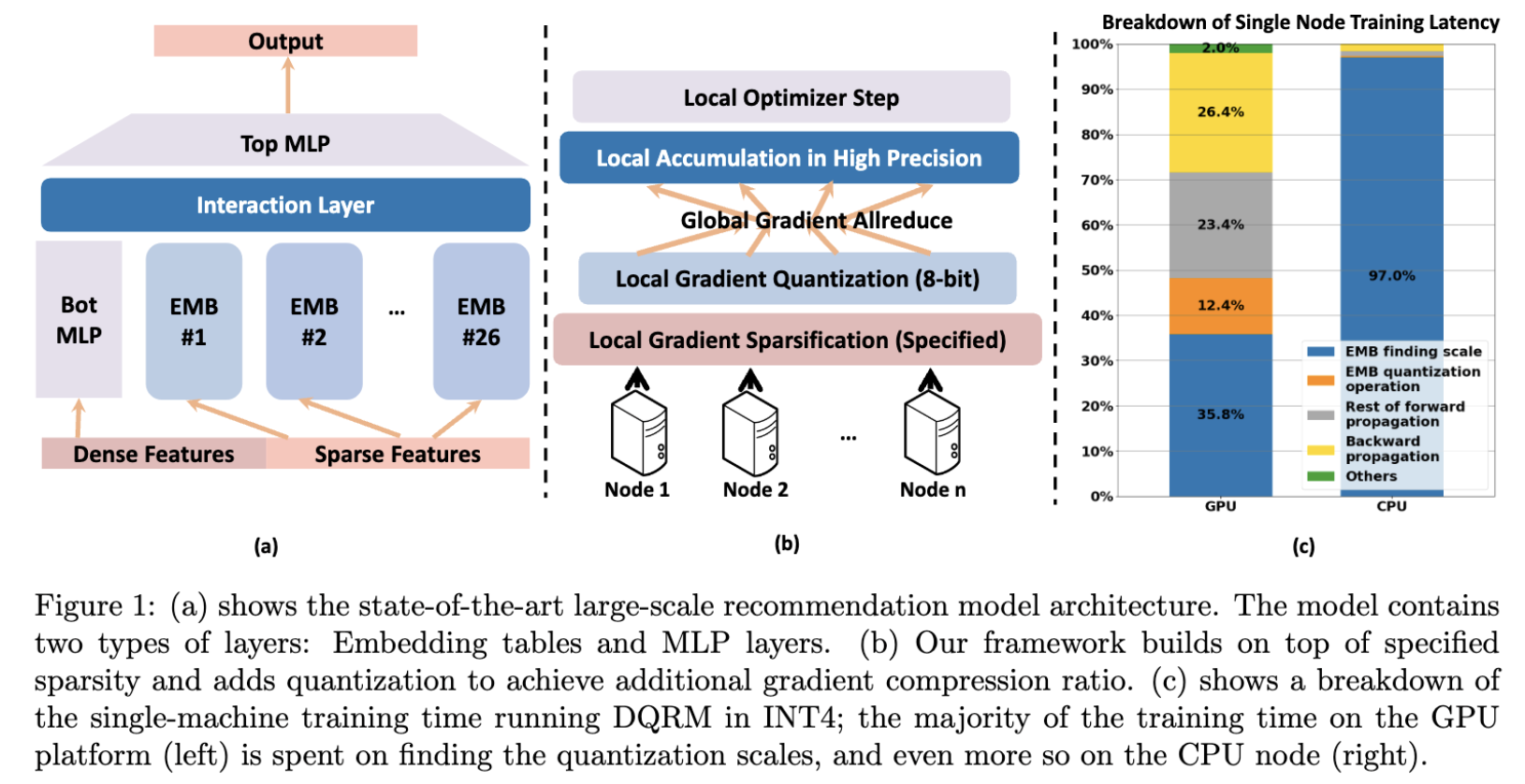
DQRM: Deep Quantized Recommendation Model
Yang Zhou, Zhen Dong, Ellick Chan, Dhiraj Kalamkar, Diana Marculescu, Kurt Keutzer Manuscript, 2023 arXiv / Code We propose a variant of DLRM that is efficient to be trained and do inference using quantization. We first show that INT4 QAT is able to give on-par/exceeds performance of FP32 DLRM. We then build a system that train the 4-bit quantized model with 1% sparse gradient. |
|
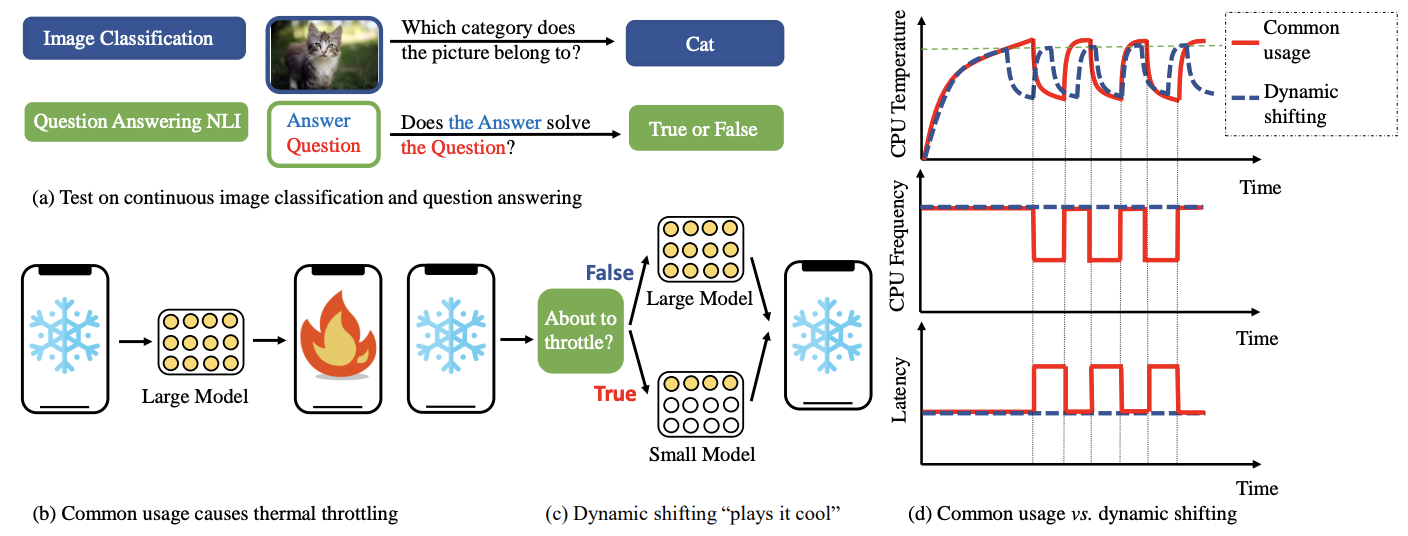
Play It Cool: Dynamic Shifting Prevents Thermal Throttling
Yang Zhou, Jeff Liang, Ting-Wu Chin, Diana Marculescu DyNN @ ICML (Oral), 2022 arXiv We notice that deploying powerful neural networks on the edge devices tends to lead to thermal emergency which force OS to throttle the frequency of CPU. We propose a dynamic shifting method to prevent thermal throttling by shifting between the weak and strong models of the same dynamic network. |
|
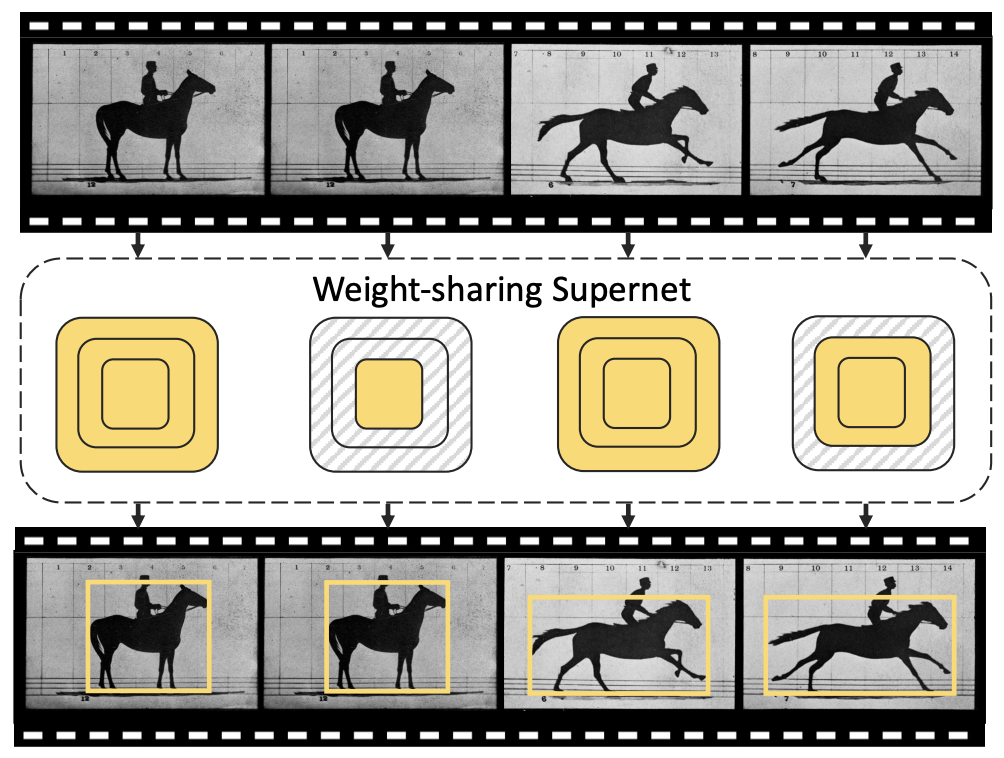
ANT: Adapt Network Across Time for Efficient Video Processing
Feng Liang, Ting-Wu Chin, Yang Zhou, Diana Marculescu CVPRW ECV, 2022 arXiv we propose the ANT framework to harness these redundancies for reducing the computational cost of video processing. The proposed ANT adapts a purpose-fit network by inspecting the semantic differences between frames. |
Selected Honors
- Carnegie Institute of Technology Dean's Fellowship, Awarded 2023-2024
- College Scholar 2023, Top 10%, University of Texas at Austin
- Distinguished College Scholar, 2022 Top 4%, University of Texas at Austin
- Distinguished College Scholar, 2021 Top 4%, University of Texas at Austin
- Engineering Honor Student, Top 10%, Oct. 2020 to May 2023
Services
Reviewer of ECCV 2023, MLsys 2024, NeurIPS 2025I am selected as "top reviewer of NeurIPS 2025".